多模態(tài)技術(shù) 概念解析與最新發(fā)展
多模態(tài)是指融合多種感知模式(如視覺(jué)、聽(tīng)覺(jué)、文本等)的信息處理與交互方式。在人工智能領(lǐng)域,多模態(tài)技術(shù)通過(guò)整合來(lái)自不同模態(tài)的數(shù)據(jù),實(shí)現(xiàn)更全面、準(zhǔn)確的認(rèn)知和理解。
多模態(tài)的基本概念涉及跨模態(tài)信息的對(duì)齊、轉(zhuǎn)換與融合。例如,在自動(dòng)駕駛系統(tǒng)中,結(jié)合攝像頭圖像(視覺(jué))、雷達(dá)數(shù)據(jù)(空間感知)和語(yǔ)音指令(聽(tīng)覺(jué))進(jìn)行決策;在智能助手應(yīng)用中,同時(shí)處理用戶的語(yǔ)音輸入和圖像信息以提供更精準(zhǔn)的服務(wù)。
近年來(lái),多模態(tài)技術(shù)取得顯著進(jìn)展。2023年,OpenAI發(fā)布的GPT-4V模型能夠同時(shí)處理文本和圖像輸入,實(shí)現(xiàn)更復(fù)雜的多模態(tài)推理。谷歌的PaLM-E模型則整合視覺(jué)與語(yǔ)言數(shù)據(jù),應(yīng)用于機(jī)器人控制。多模態(tài)大模型在醫(yī)療診斷、教育、娛樂(lè)等領(lǐng)域的落地案例不斷增多,顯示出強(qiáng)大的應(yīng)用潛力。
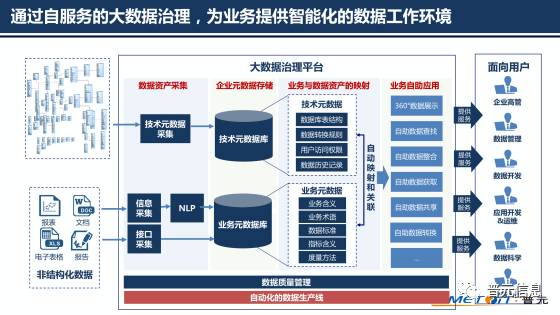
數(shù)據(jù)處理服務(wù)在多模態(tài)技術(shù)中扮演關(guān)鍵角色。由于多模態(tài)數(shù)據(jù)具有異構(gòu)性(如圖像像素、文本序列、音頻波形),專業(yè)的數(shù)據(jù)處理服務(wù)包括:數(shù)據(jù)清洗與標(biāo)注(如圖像分割、語(yǔ)音轉(zhuǎn)文本)、跨模態(tài)對(duì)齊(如時(shí)間同步的視聽(tīng)數(shù)據(jù))、特征提取與融合(如使用Transformer架構(gòu)整合多模態(tài)特征)。這些服務(wù)為模型訓(xùn)練提供高質(zhì)量、標(biāo)準(zhǔn)化的數(shù)據(jù)基礎(chǔ),顯著提升多模態(tài)系統(tǒng)的性能與可靠性。
多模態(tài)技術(shù)將繼續(xù)深化感知與認(rèn)知的融合,推動(dòng)人工智能向更人性化的交互方式發(fā)展,而高效的數(shù)據(jù)處理服務(wù)將是其規(guī)模化應(yīng)用的重要支撐。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.gihiglx.cn/product/11.html
更新時(shí)間:2026-03-09 10:05:08